Interactive Object Detection
Juergen Gall, Angela Yao, Christian Leistner, and Luc Van Gool
Abstract
In recent years, the rise of digital image and video data available has led to an increasing demand for image annotation. In this paper, we propose an interactive object annotation method that incrementally trains an object detector while the user provides annotations. In the design of the system, we have focused on minimizing human annotation time rather than pure algorithm learning performance. To this end, we optimize the detector based on a realistic annotation cost model based on a user study. Since our system gives live feedback to the user by detecting objects on the fly and predicts the potential annotation costs of unseen images, data can be efficiently annotated by a single user without excessive waiting time. In contrast to popular tracking-based methods for video annotation, our method is suitable for both still images and video. We have evaluated our interactive annotation approach on three datasets, ranging from surveillance, television, to cell microscopy.
Images/Videos
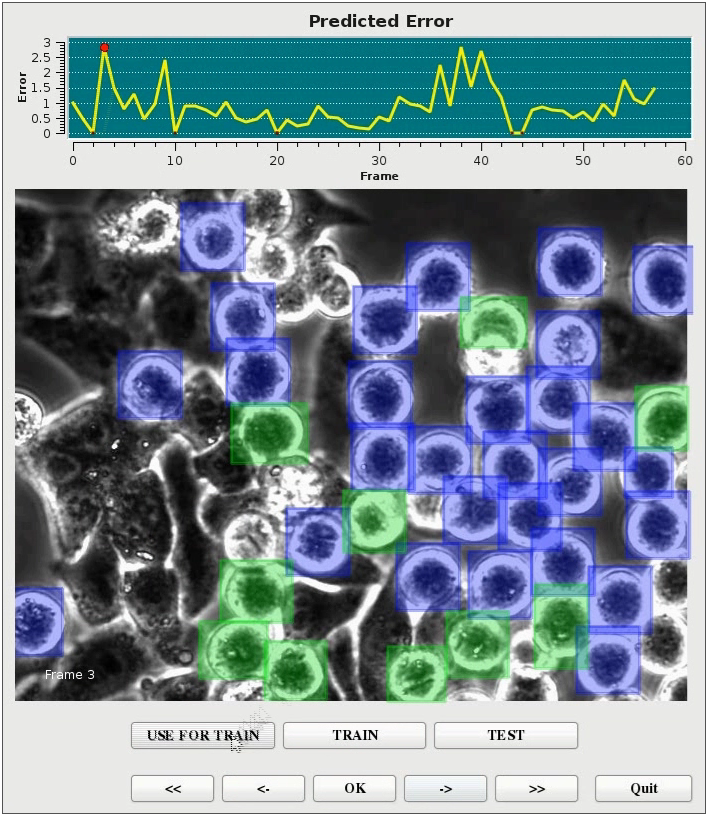
Example from our interactive object detection framework for annotation. While blue bounding boxes denote detections by the system, the green bounding boxes are annotated by the user. The yellow graph denotes the predicted annotation cost, i.e., the cost to correct all detection errors in an image. The predicted annotation cost allows the user to select images for correcting detections and updating the object detector.
Publications
Yao A., Gall J., Leistner C., and van Gool L., Interactive Object Detection (PDF), IEEE Conference on Computer Vision and Pattern Recognition (CVPR'12), 3242-3249, 2012. ©IEEE